ニュース
チューリング、日本初の自動運転向けVLA(Vision-Language-Action)モデルデータセット「CoVLA Dataset」を発表、WACV2025に論文が採択
2024年9月10日
チューリング、日本初の自動運転向けVLA(Vision-Language-Action)モデルデータセット
「CoVLA Dataset」を発表、WACV2025に論文が採択
新たに自動運転マルチモーダルモデルのベースとなる日本語LLMも公開、国内最高レベルの性能を達成
完全自動運転技術の開発に取り組むTuring株式会社(東京都品川区、代表取締役:山本 一成、以下「チューリング」)は、日本初(※)の自動運転向けVLAモデルデータセット「CoVLA(コブラ) Dataset」を開発し、一部を公開しました。そして、コンピュータービジョンの主要な国際会議WACV 2025(IEEE/CVF Winter Conference on Applications of Computer Vision 2025)において、同データセットの研究論文「CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving」(以下、本論文)が採択されたことをお知らせします。
本成果は経済産業省/NEDOの生成AI開発支援「GENIAC」の開発の一環として実施され、上記のほかにも、自動運転マルチモーダルモデルのベースとなる日本語LLM「LIama-3-heron-brain-70B,8B」や、高速なマルチモーダル分散学習ライブラリ「vlm-recipes」、大規模な視覚-言語データセット「Wikipedia-Vision-JA」、「Cauldron-JA」など複数成果を公開しています。
※自社調べ、2024年9月調査、日本国内における自動運転向けVLAモデルとして
背景
複雑かつ予期しない状況下においても適切に対応可能なシステムを構築する必要がある完全自動運転では、画像(視覚)やテキスト(言語)など複数種類のデータを用いて高度な判断を行うことができるマルチモーダル大規模言語モデル (以下、MLLMs)が重要な技術となります。しかし、同領域においてはAI学習用にアノテーションされた大規模なデータセットが不足していることがボトルネックとなり、E2E自動運転システム(※)の経路計画における応用研究がほとんど見られないのが現状です。
CoVLA Datasetの概要
CoVLA (Comprehensive Vision-Language-Action) Datasetは、上記課題を解決するためにチューリングが開発し、このたび一部を公開した日本初の自動運転向けVLAモデルデータセットです。車載センサーデータを含む80時間以上の運転データで構成されており、データの規模とアノテーションの多様さにおいて国外の既存データセットを上回っています。データ処理からキャプション生成まで自動化したスケーラブルな手法で構築しており、同データセットを用いて開発したVLAモデル「CoVLA-Agent」は、画像から得た運転環境を自然言語で詳細に説明し、適切な経路計画を生成することが可能です。
CoVLA-Dataset:https://huggingface.co/datasets/turing-motors/CoVLA-Dataset-Mini
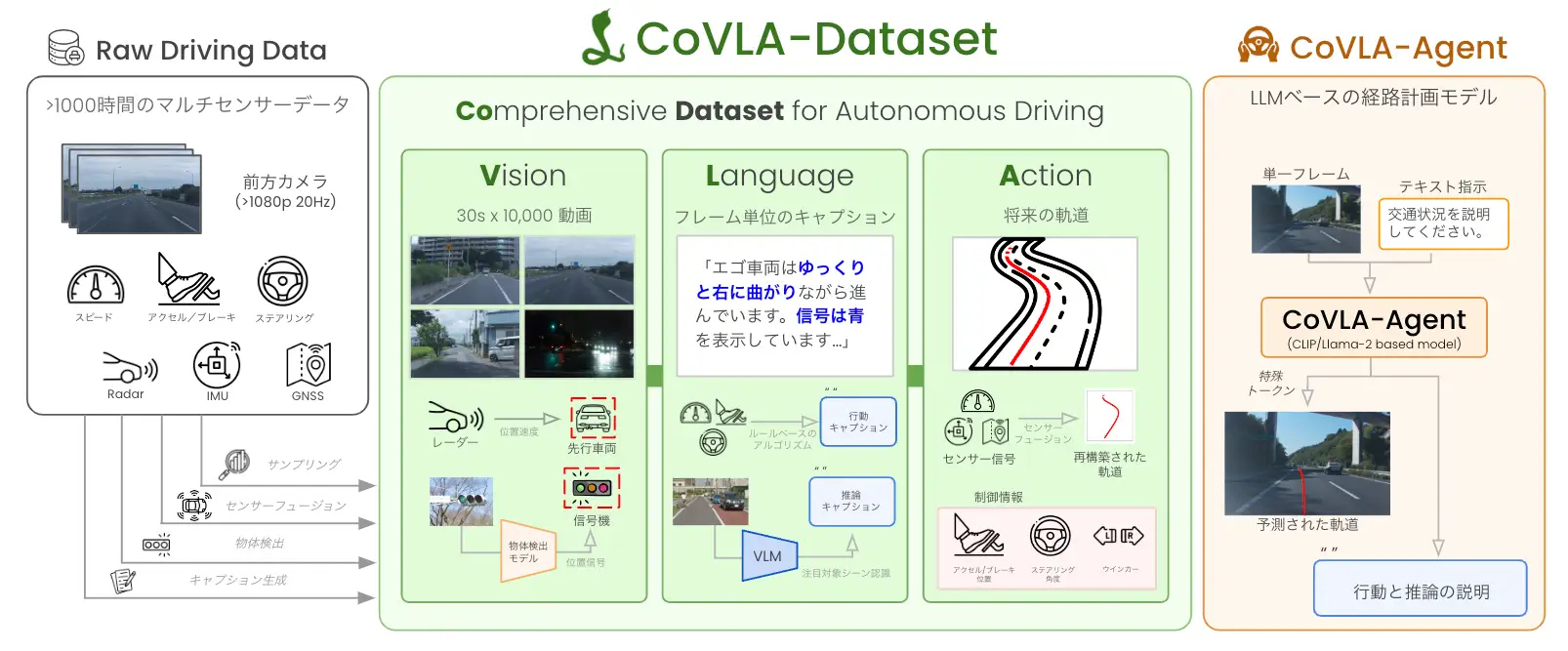
CoVLA概要図 |
今後について
CoVLA Datasetを活用したMLLMsがさまざまな運転シナリオにおいてどの程度の能力を発揮するかを検証した結果、同モデルが一貫性のある言語生成と行動出力において優れた性能を示し、視覚・言語・行動データを用いたVLAモデルが自動運転分野において効果的なアプローチであることを確認しています。
今後は、学術機関向けにCoVLA Datasetの全データセットを公開することも視野に、より安全かつ信頼性の高い自動運転システムの実現を目指していきます。
本論文は、arXivにて公開しています:https://arxiv.org/abs/2408.10845
日本語LLM「LIama-3-heron-brain-70B,8B」について
Llama-3-heron-brain-70B, 8Bは、日本の言語ニュアンスや道路状況を詳細に理解し、対応可能な指示学習済みの日本語LLMです。自動運転に向けた視覚-言語マルチモーダルモデルをベースにしており、Llama-3に対して日本語での継続事前学習を実施した後、さらに追加の指示調整を実施しています。GENIACプロジェクトで言語性能を測る共有ベンチマークにおいてはgpt-3.5-turboを上回る結果を示し、事業者間でも2番目のスコアを記録するなど、高い日本語・英語性能を有しています。また、これらをベースとした最大730億パラメータの視覚-言語モデルについても学習を実施しており、開発・評価を進めています。
LIama-3-heron-brain-70B,8B:https://huggingface.co/turing-motors/Llama-3-heron-brain-70B-v0.3
Llama-3-heron-brain-8B-v0.3:https://huggingface.co/turing-motors/Llama-3-heron-brain-8B-v0.3
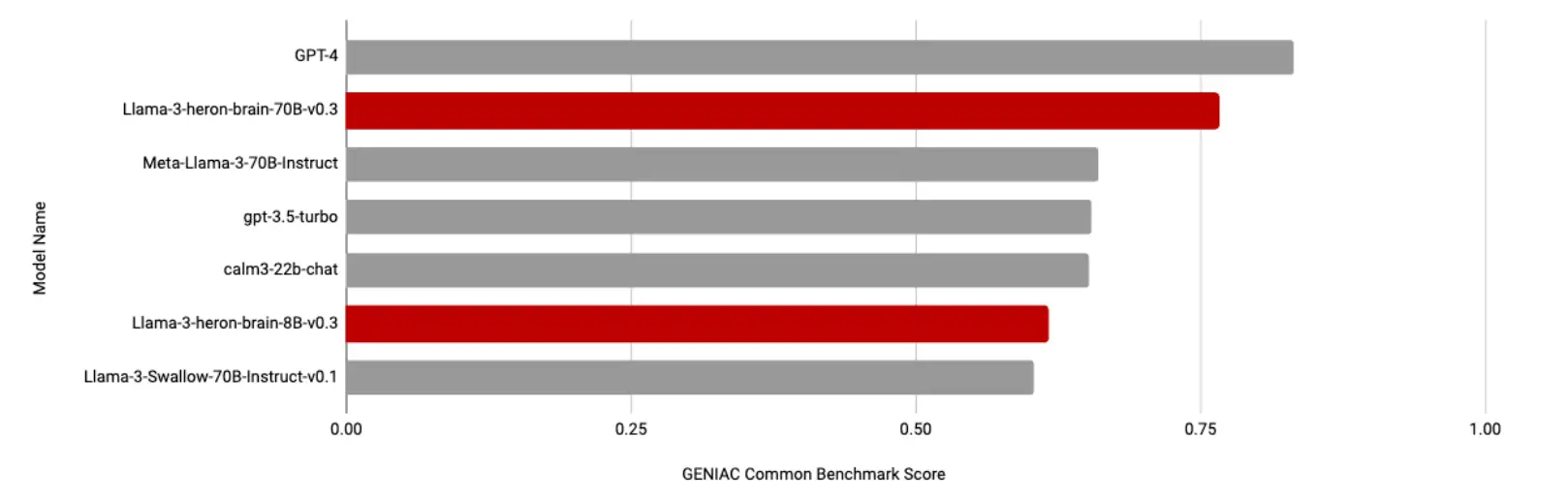
各モデルのスコア比較 |
視覚-言語データセット「Wikipedia-Vision-JA」「Cauldron-JA」について
日本語LLMに視覚情報を結合させるためには、大規模な画像とテキストのペアを学習させる必要があります。そこで、チューリングは日本の文化・応答に密結合した日本語と画像のデータセットを新たに構築しました。Wikipedia-Vision-JAは、日本語Wikipediaの全ページの情報から、画像とその説明、関連テキストからなる約600万件のデータセットです。また、Cauldron-JAは、Hugging Faceが公開している「The Cauldron」を日本語で再構成した視覚言語モデル データセットで、視覚言語応答に関する44のデータセットを含む大規模なコレクションです。
Wikipedia-Vision-JA:https://huggingface.co/datasets/turing-motors/Wikipedia-Vision-JA
Cauldron-JA:https://huggingface.co/datasets/turing-motors/Cauldron-JA
マルチモーダル分散学習ライブラリ「vlm-recipes」について
vlm-recipes は、チューリングがGENIACプロジェクトで大規模な視覚-言語マルチモーダルモデルを学習するために活用した分散学習ライブラリです。マルチモーダルモデルのトレーニングを簡単かつ効率的に行うために設計されたツールで、バックエンドとして PyTorch FullyShardedDataParallel (FSDP) を使用することで、大規模な GPU クラスターでの分散トレーニングをサポートしています。直感的なインターフェースと柔軟な構成オプションにより、あらゆる VLM アーキテクチャやデータセットでのトレーニングを簡単に管理することができます。より多くの研究者や開発者がより簡単に大規模マルチモーダルモデルを学習できるようにするため、オープンソースとして公開しています。(開発責任者:藤井一喜)
vlm-recipes:https://github.com/turingmotors/vlm-recipes
本プレスリリースにおける成果は、国内における生成AIの開発力強化を目的としたGENIACプロジェクトのもと、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)による助成事業「競争力ある生成AI基盤モデルの開発」から得られた結果に基づき公開しています。
参考プレスリリース:https://tur.ing/posts/DK4fM1yr
※カメラから取得したデータのみでステアリング、アクセル、ブレーキなど、運転に必要なすべての判断をAIが行うシステム
チューリングについて
完全自動運転の開発に取り組むスタートアップです。カメラから取得したデータのみでステアリング、アクセル、ブレーキなど、運転に必要なすべての判断をAIが行うE2E (End-to-End) の自動運転システムを開発しています。複数種類のデータを用いて高度な判断を行うマルチモーダル生成AI「 Heron」や、現実世界の物理法則や物体間の相互作用など複雑な状況を理解し、リアルな運転シーンを動画として生成可能な自動運転向け生成世界モデル「 Terra」の開発を通じて自動運転領域における技術革新を推進し、2030年までにハンドルのない完全自動運転車の開発を目指しています。
会社概要
会社名:Turing株式会社
所在地:東京都品川区大崎1丁目11−2 ゲートシティ大崎 イーストタワー4階
代表者:代表取締役 山本一成
設立:2021年8月
事業内容:完全自動運転車両の開発
URL:https://tur.ing/
採⽤情報
チューリングは、日本発の完全自動運転実現により世界を変える仲間を積極的に募集しています。会社紹介イベントや自動運転体験会も頻繁に実施していますので、お気軽にお問い合わせください。
採⽤ページ:https://tur.ing/jobs
TURING株式会社 ホームページはこちら




